The role of a data lake in healthcare analytics is essential in that it creates broad data access and usability across the enterprise. It has symbiotic relationships with an enterprise data warehouse and a data operating system.
To avoid turning the data lake into a black lagoon, it should feature four specific zones that optimize the analytics experience for multiple user groups:
1. Raw data zone.
2. Refined data zone.
3. Trusted data zone.
4. Exploration zone.
Each zone is defined by the level of trust in the resident data, the data structure and future purpose, and the user type.
Understanding and creating zones in a data lake behooves leadership and management responsible for maximizing the return on this considerable investment of human, technical, and financial resources.
 Download
Download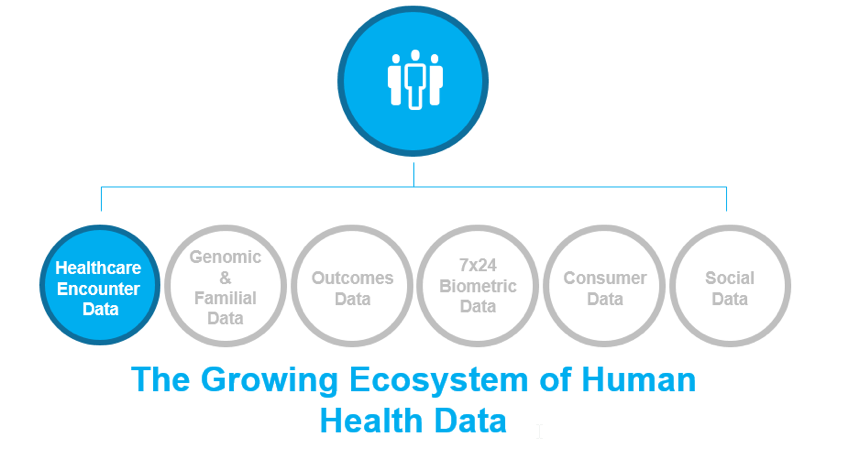
Health Catalyst has published articles describing early- and late-binding data warehouse architectures, comparing data lakes to data warehouses, and explaining how health systems can leverage unique data lake functions within their existing analytic platforms.
The evolving healthcare data environment created the need for data lakes, but they are a significant IT investment. Understanding the relationship between an enterprise data warehouse (EDW) and a data lake, as well as the structural components of a data lake—the zones—is fundamental to investing in the right technology with the appropriate financial and human resources.
In healthcare today, outcomes improvement efforts are fueled by limited information, primarily healthcare encounter data (Figure 1).
To see more of the picture, bring it into focus, and understand what really impacts outcomes, we need genomic and familial data, outcomes data, 7×24 biometric data, consumer data, and socio-economic data. The complete ecosystem of data necessary for massive outcomes improvements will increase the total amount of healthcare data tenfold. According to a 2014 IDC report, the healthcare digital universe is growing 48 percent per year. In 2013, the industry generated 4.4 zettabytes (1021 bytes) of data. By 2020, it will generate 44 zettabytes. Unfortunately, this data volume would explode the data warehouse of most organizations. Fortunately, a data lake can handle this volume.
The benefits of a data lake as a supplement to an EDW are numerous in terms of scale, schema, processing workloads, data accessibility, data complexity, and data usability:
A data lake can scale to petabytes of information of both structured and unstructured data and can ingest data at a variety of speeds from batch to real-time. Unfortunately, these capabilities have led to a negative side effect. Gartner’s hype cycle for 2017 shows that data lakes have passed the “peak of inflated expectations” and have started the slide into the “trough of disillusionment.” This isn’t surprising. Often, an industry develops a concept thinking it will solve world hunger, then learns its real-life limitations.
Initially, data lakes were predicted to solve all of healthcare’s outcomes problems, but they have ended up just collecting petabytes of data. Now, data lake users see a lot of detritus that can’t be used to build anything. The data lake has become a data swamp.
Understanding and creating zones within a data lake are the keys to draining the swamp.
Data lake zones form a structural governance to the assets in the data lake. To define zones, Zaloni excerpts content from the ebook, “Big Data: Data Science and Advanced Analytics.” The book’s authors write that “zones allow the logical and/or physical separation of data that keeps the environment secure, organized, and agile.” Zones are physically created through “exclusive servers or clusters,” or virtually created through “the deliberate structuring of directories and access privileges.”
Healthcare analytics architectures need a data lake to collect the sheer volume of raw data that comes in from the various transactional source systems used in healthcare (e.g., EMR data, billing data, costing data, ERP data, etc.). Data then populates into various zones within the data lake. To effectively allocate resources for building and managing the data lake, it helps to define each zone, understand their relationships with one another, know the types of data stored in each zone, and identify each zone’s typical user.
Data lakes are divided into four zones (Figure 2). Organizations may label these zones differently according to individual or industry preference, but their functions are essentially the same.

In the raw zone data is moved in its native format, without transformation or binding to any business rules. Often the only organization or structure added in this layer is outlining what data came from what source system. Health Catalyst calls those areas in the raw zone source marts. Though all data starts in the raw zone, it’s too vast of a landscape for less technical users. Typical users include ETL developers, data stewards, data analysts, and data scientists, who are defined by their ability to derive new knowledge and insights amid vast amounts of data. This user base tends to be small and spends a lot of time sifting through data, then pushing it into other zones.
Source data is ingested into the EDW, then used to build shared data marts in the trusted data zone. Terminology is standardized at this point (e.g., RxNorm, SNOMED, etc.). The trusted data zone holds data that serves as universal truth across the organization. A broader group of people has applied extensive governance to this data, which has more comprehensive definitions that the entire organization can stand behind. Trusted data could include building blocks, such as the number of ED visits in a certain period, inpatient admission rates from one year to the next, or the number of members in risk-based contracts.
Meaning is applied to raw data so it can be integrated into a common format and used by specific lines of business. Data in the refined zone is grouped into Subject Area Marts (SAMs, often referred to as data marts). A department manager looking for end-of-month numbers would query a SAM rather than the EDW. SAMs become the source of truth for specific domains. They take subsets of data from the larger pool and add value that’s meaningful to a finance, clinical, operations, supply chain, or other administrative area.
Refined data is used by a broad group of people, but is not yet blessed by everyone in the organization. In other words, people beyond specific subject areas may not be able to derive meaning from refined data. A SAM gets promoted to the trusted zone when the definitions applied to its data elements have broadened to a much larger group of people.
Anyone can decide to move data from the raw, trusted, or refined zones into the exploration zone. Here, data from all of these zones can be morphed for private use. Once information has been vetted, it is promoted for broader use in the refined data zone.
For an example of the data type in each zone, consider length of stay (LOS). There are dozens of ways to define LOS using ED presentation time, admit time, registration time, cut time, post-observation time, and discharge time. The clinical definition of LOS for an appendectomy may be from cut time to discharge time, but the corporate definition may be from admit time to discharge time. A SAM that focuses on appendectomy might choose to use the clinical definition, which doesn’t apply to the global definition (i.e., the definition in the trusted zone). For an individual SAM definition of LOS to be promoted to the trusted zone, it needs to be vetted through a broader group of people to confirm it has universal application.
Directors who have financial responsibility over a single line of business may need to evaluate their department’s productivity. They may need to see things a certain way, such as excluding corporate overhead, over which they have no control. This is what makes the SAM more specific to one area. The data definition has been vetted and agreed to by a group of people, though it has yet to reach global agreement.
Different technology can run on top of different zones in a data lake. The data lake itself typically runs on Hadoop, which is optimal for handling huge data volumes. Relational Databases like SQL Server are more user friendly and will provide data to a larger user base. SQL queries can run on top of Hadoop to produce data marts and SAMs in the trusted and refined zones.
Hortonworks refers to a Connected Data Architecture, in which “data pools need to ensure that connected data can flow freely to the place where it is optimal for the business to get value from it.” Zones may not live on the same data technology. Much of the data will live in a data lake, but more refined zones may have a portion of their data that resides in an EDW or smaller data marts.
Partnering the appropriate technology to each zone lowers the barrier to entry for associated user groups.
Earlier, we said that huge data volumes have turned data lakes into data swamps, which is remedied through a larger healthcare analytics ecosystem. Some, or all, of a data operating system can be deployed over the top of any healthcare data lake. The Health Catalyst® Data Operating Syste (DOS™) (Figure 3) can index, catalog, analyze, and provide insights from the terabytes and growing data assets in a health system: attributes that can provide IT departments, clinicians, population health managers, financial leaders, and health system leaders with the knowledge they need to produce massive outcomes improvements.
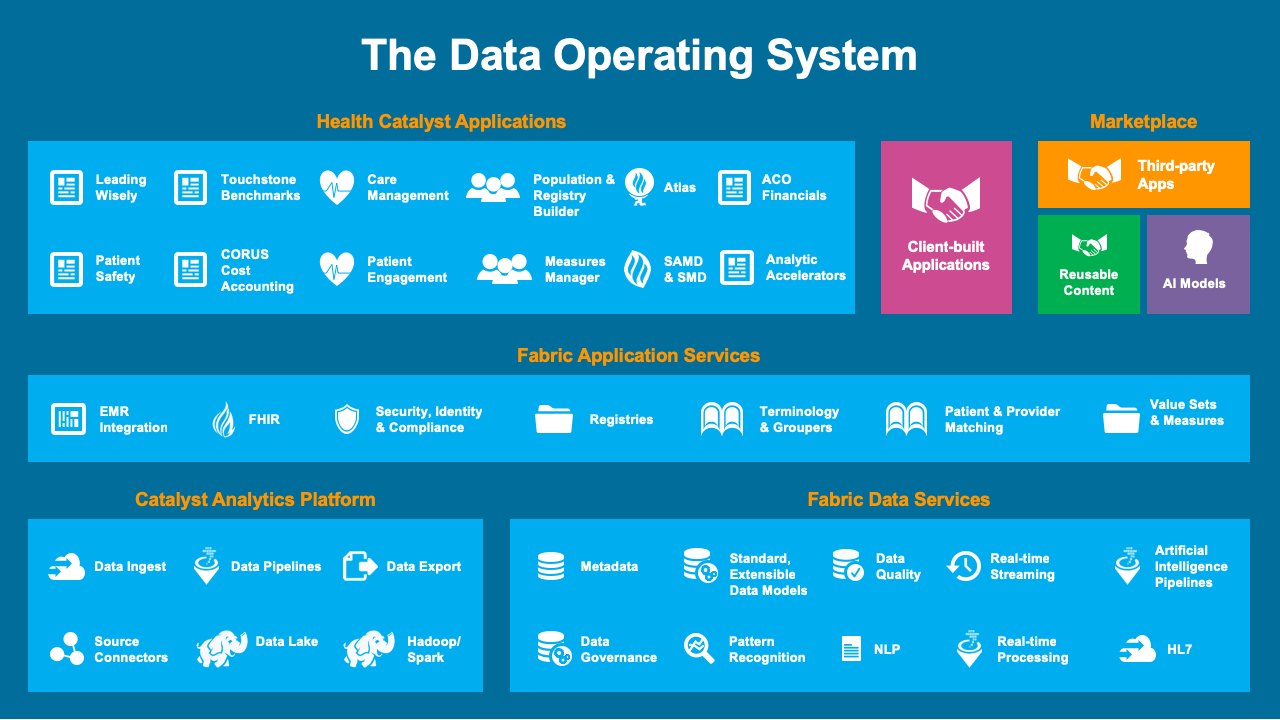
DOS enables a data lake to be built with the required governance and meaning added to the data so it is easily organized into the appropriate zones. Data can then be used according to zone by the various data consumers in a health system. DOS also allows data to be analyzed and consumed by the Fabric Services layer to accelerate the development of innovative data-first applications.
The volume of healthcare data is mushrooming, and data architectures need to get ahead of the growth. Vast volumes of data will continue to flow into the EDW.
A data lake is required to make data accessible to a subset of ETL developers, data stewards, data analysts, and data scientists. Data lakes allow data to be moved into various zones for experimentation and research, or for customization into shared data marts and SAMs.
To prevent data lakes from becoming mired in the petabytes of data now swamping healthcare, the new architecture presented by the data operating system offers a breakthrough in analytics engineering that can renew the life of a data lake and accommodate the big-bang growth of healthcare data.
Would you like to use or share these concepts? Download presentation highlighting the key main points.
Click Here to Download the Slides
https://www.slideshare.net/slideshow/embed_code/key/gnvYsx8L9mOoea




