It can be confusing to know whether or not your health system needs to add a data warehouse unless you understand how it’s different from a clinical data repository. A clinical data repository consolidates data from various clinical sources, such as an EMR, to provide a clinical view of patients. A data warehouse, in comparison, provides a single source of truth for all types of data pulled in from the many source systems across the enterprise. The data warehouse also has these benefits: a faster time to value, flexible architecture to make easy adjustments, reduction in waste and inefficiencies, reduced errors, standardized reports, decreased wait times for reports, data governance and security.
When I work with healthcare organizations to teach them how to unlock the value of their data, I hear a lot of talk about how important it is to have a tool like a clinical data repository. But in my experience, this belief is limiting: a clinical data repository is just that—a repository.
Even though a clinical data repository is good at gathering data, it can’t provide the depth of information necessary for cost and quality improvements because it wasn’t designed for this type of use. Instead, what health systems need is a flexible, late-binding enterprise data warehouse (EDW). With its unique ability to flexibly tie disparate data sources from across the organization into one source of truth, health systems will realize a significant return of investment (ROI) from their newfound ability to quickly and easily pull and analyze data for every service in the organization.
Because there are so many misperceptions around what a clinical data repository offers versus a late-binding data warehouse, I’d like to discuss the pros and cons of each one.
Clinical Data Repository
A clinical data repository consolidates data from various clinical sources, such as an EMR or a lab system, to provide a full picture of the care a patient has received. Some examples of the types of data found in a clinical data repository include demographics, lab results, radiology images, admissions, transfers, and diagnoses.
While the data contained in a clinical repository is valuable because it shows a patient’s clinical data, the design is not an adequate solution for health systems for numerous reasons. The primary reason is this: clinical data repositories don’t offer flexible analytics for analysts to use as they work to improve patient care. These repositories function simply as a database that holds clinical data. In most cases, they also don’t have the ability to integrate with other non-clinical source systems, eliminating the chance to follow patient care across the care continuum. Because of this major limitation, clinical data repositories can’t provide a true picture of the cost per case for each patient. They also can’t show patient satisfaction scores for each visit, which means they’re inadequate for quality and cost improvement projects. There are other limitations as well.
Clinical data repositories are inefficient. It’s important for clinicians to be able to access their data to generate reports. But when clinicians request many reports all at once, the IT team in charge of the system turns into a report factory rather than functioning as an experienced analytics team. As a result, these highly skilled, highly paid IT employees end up spending their time tracking down the data, pulling it into the repository, spitting out reports, and moving on to the next task, rather than working with the clinical teams to refine the report to show valid data and meet their hopes and expectations.
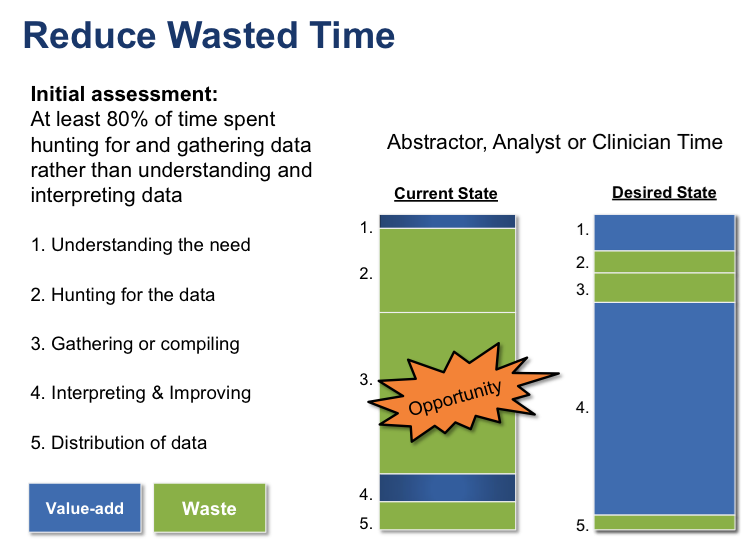
When data analysts work with fragmented source systems in a siloed environment, they spend the majority of their time hunting and gathering data rather than interpreting it, leaving a tremendous opportunity to improve efficiency by using a centralized data environment.
There’s a large margin for costly errors. Clinical data repositories often use complex data models and their structure is normalized. Because of this complexity, the report writer will join many different tables in one report, increasing the margin for error during coding and the time it takes to build these reports. For example, a code field, such as ICD9 code 453.2, may exist in a table while all the descriptions for the codes exist in a lookup table. For the report writer to get a description that tells them 453.2 is the code for “other venous embolism and thrombosis of inferior vena cava,” they need to join the lookup table with the original table. In addition, the normalized approach means extra work with the SQL to get the reports to look the way you want so it’s easier to understand the data in each field.
Reports aren’t standardized. When data is being pulled from clinical data repositories and then different visualization tools are used to build those reports, each report will look and function differently. Without a centralized tool for reporting across the organization, reporting will continue to have a different look and feel by department or functional area, making report reading less efficient.
Tools aren’t standardized. When tools aren’t standardized, users of the tools, such as clinicians or analysts, need to learn how to use each tool to generate their reports. This lack of standardization is frustrating. Plus, learning how to use each tool adds to the time and cost of reporting.
Data isn’t always secure. When data is spread across many clinical data repositories, there is no way to audit who is looking at the data, which can be deadly for maintaining a secure organization. Even built-in safeguards within those systems are limited; the minute someone copies data from a system to a shared drive, or another unprotected database—despite the best of intentions the data will be used alongside data from another system—it becomes extremely vulnerable, exposing the hospital or health system to needless risk.
Late-Binding Enterprise Data Warehouse
While the patient level care information the clinical data repository provides is important, there’s a better solution that will provide a single source of truth across the entire health system: a Late-Binding™ Data Warehouse.
By nature of the late-binding design (extracting and binding data later rather than earlier) the entire organization will have access to the knowledge they need, not just those services that have the budget to hire their own analyst. By pulling all this data into a single source of organizational truth, analysts can provide reliable and repeatable reports. There are other benefits to a Late-Binding data warehouse as well:
Faster time to value. With a Late-Binding Data Warehouse, you don’t need to wait months or years to map all your data. Instead, you can start small, pulling in and binding only the data you need for specific initiatives. This makes it possible to achieve a much faster time to value, and have the opportunity to demonstrate the benefits in order to gain the support of clinicians for additional analytics and quality improvement initiatives in the future.
Flexible architecture means easy adjustments. The flexibility of a Late-Binding Data Warehouse is critical because of the simple fact that healthcare definitions change rapidly and frequently. A new research report, a greater understanding of how the human body works, a change in protocols or regulations, new technologies, and dozens of other factors can influence these definitions. With an early binding schema, it’s very time-consuming and costly to make changes. A Late-Binding architecture, however, makes it much easier to make these adjustments. An example of the importance of late-binding comes from my work with Texas Children’s Hospital. We had a project where we had to bring in a lot of data to answer a few questions for The Joint Commission according to their specific sets of inclusion and exclusion criteria. We met their reporting requirements by using a Late-Binding Data Warehouse. Six months later, Texas Children’s joined the Leapfrog Group coalition, which had its own set of inclusion and exclusion criteria. If we had used an early-binding schema, satisfying the new reporting requirements would have involved rebuilding the definitions, a substantial amount of work. But because we used a Late-Binding Data Warehouse, it was relatively simple to create the new report.
Reduction in waste and inefficiencies. Instead of analysts using their precious time to hunt down data, they spend time doing what they’re good at—adding value to the organization. With a one-stop shop for data and a place that requires only one login to get any data in the system, analysts now have a place to analyze data; they no longer need to cobble the data together for their reports. This reduces the expenses of recreating new reports when the analyst needs to make changes to the definitions and parameters. Plus, analysts can focus on improvement projects alongside clinical teams rather than simply tracking down the data for each report.
Reduced errors means reduced costs. A Late-Binding architecture decreases the possibility of expensive errors. When analysts need to perform data validation to ensure the data in the reports matches the source data, they can easily return to the source system to see what source field and which source table that column came from.
Reports are standardized. Reports from a Late-Binding Data Warehouse look the same across the entire organization. Once there’s an EDW team in place, their goal is to treat every service as a customer and provide standardized reports with the same look and feel. This approach contributes to a more systematized, unified organization.
No more long wait times. IT departments are usually overwhelmed with requests, and it can take a long time for an analyst to respond to the next request in the queue. By the time they’re able to work on the report, the clinician’s specifications and requirements may have already changed. With a Late-Binding Data Warehouse, however, and a dedicated, enterprise team, service lines will have their own resource whose role is to work with them to produce meaningful reports and make alterations as needs and wants change.
Data is secure. With a Late-Binding Data Warehouse, the organization now has a central, secure repository for all data within the organization. Individual departments can still maintain their own repositories (although they may want to re-think that strategy after experiencing a full EDW) but their data is now visible to all authorized users. In addition, alarms and alerts can be set for unauthorized access, giving the organization tighter control over its data.
Realizing Return on Investment with a Late-Binding Enterprise Data Warehouse
Most healthcare organizations have hundreds of different technology solutions they’ve purchased from multiple vendors, but they don’t have a way to extract the data from these different solutions into one single source of truth. The lack of systematization decreases the organization’s ability to see a favorable return on investment because they can’t access the depth of data that’s stored in so many various source solutions. And while clinical data repositories can be a useful tool, they simply cannot offer the flexibility and scalability a Late-Binding Data Warehouse provides. A Late-Binding Data Warehouse can incorporate all the disparate data from across the organization (clinical, financial, operational, etc.) into a single source of truth, which leads to greater insights into the data and a better return on investment in the short-, mid- and long-term for healthcare organizations.
The Health Catalyst Data Operating System (DOS™) Helps Healthcare Organizations Move Beyond the Data Warehouse
Traditional data warehousing, which solved some of the data integration issues facing healthcare organizations, is no longer good enough. As Gartner reported, traditional data warehousing will be outdated and replaced by new architectures by the end of 2018. And current applications are no longer sufficient to manage these burgeoning healthcare issues. The technology is now available to change the digital trajectory of healthcare.
The Health Catalyst Data Operating System (DOS™) is a breakthrough engineering approach that combines the features of the late-binding data warehousing approach discussed above, clinical data repositories, and health information exchanges in a single, common-sense technology platform.
DOS offers the ideal type of analytics platform for healthcare because of its flexibility. DOS is a vendor-agnostic digital backbone for healthcare. The future of healthcare will be centered around the broad and more effective use of data from any source. Clinical and financial decision support at the point of care is almost nonexistent in healthcare, restricted to a few pioneering organizations that can afford the engineering and informatics staff to implement and maintain it. With DOS, this kind of decision support is affordable and effective, raising the value of existing electronic health records and making new software applications possible
PowerPoint Slides
Would you like to use or share these concepts? Download this presentation highlighting the key main points.
 Download
Download