In addition to driving COVID-19 understanding within the United States, a national disease registry is informing research beyond U.S. borders. Clinicians with the Singapore Ministry of Healthcare Office for Healthcare Transformation (MOHT) have used Health Catalyst Touchstone® COVID-19 data to develop a machine learning tool that helps predict the likelihood of COVID-19 mortality.
With this national data set that leverages deep aggregated EHR data, the MOHT accessed the research-grade data it needed to build a machine-learning algorithm that predicts risk of death from COVID-19.
The registry-informed prediction model was accurate enough to stand up to comparisons in the published literature and promises to help inform vaccine research and, ultimately, allocation of vaccines within populations.

The COVID-19 outbreak has been a significant U.S. and global concern, given the speed of spread and breadth of health impacts (both known and unknown) on the population level. The virus causes fever, cough, lack of smell, fatigue, and mild to severe respiratory complications, which, if very severe, can lead to patient death. Meanwhile, incomplete, non-transparent, and out-of-date COVID-19 data is one of the main barriers to understanding and managing the virus nationally and abroad, as well as developing a vaccine. To circumvent the lack of real-world, research-grade evidence, researchers are looking to innovative sources of comprehensive, real-time COVID-19 data.
A national COVID-19 data set that leverages deep aggregated EMR data delivers the depth and breadth of understanding researchers need to manage the virus and develop a vaccine. The Health Catalyst Touchstone® COVID-19 Registry and Insights, for example, includes de-identified data from 80 million patients across the United States and tracking data from three national sources—Johns Hopkins University, the New York Times, and The COVID Tracking Project. With such broad data access, data analysts can leverage data on a national scale to drive population-level insights about surveillance, testing, capacity planning, and treatment response.
Touchstone and the national COVID-19 registry also promise to inform research beyond U.S. borders. In the summer of 2020, the Singapore Ministry of Healthcare’s (MOH) Office for Healthcare Transformation (MOHT), in collaboration with Health Catalyst, used Touchstone COVID-19 data to develop a machine learning tool that helps predict the likelihood of COVID-19 mortality—a critical insight for driving care to highest-risk patients and managing the outbreak on a population level. To validate the accuracy of their predictive tool, Health Catalyst compared its results with results published in the literature and determined its registry-informed research aligned closely to peer-reviewed publications.
“For a rapidly evolving situation like COVID-19, medical researchers can’t rely solely on clinical trials for guidance,” explains Praveen Deorani, Senior Data Scientist, for the Singapore MOHT. “As a practical alternative to informing medical decisions, a machine learning model can generate and analyze real-world evidence much faster.”
In an effort to assist neighboring countries that may not have the research resources available, the Singapore MOHT sought to provide analytic tools to assist in managing the pandemic. However, Singapore’s population size and the strict control measures implemented in Singapore combined to limit both the nation’s number of COVID-19 cases and the COVID-19 mortality rate, leaving a dearth of data to power predictive tools.
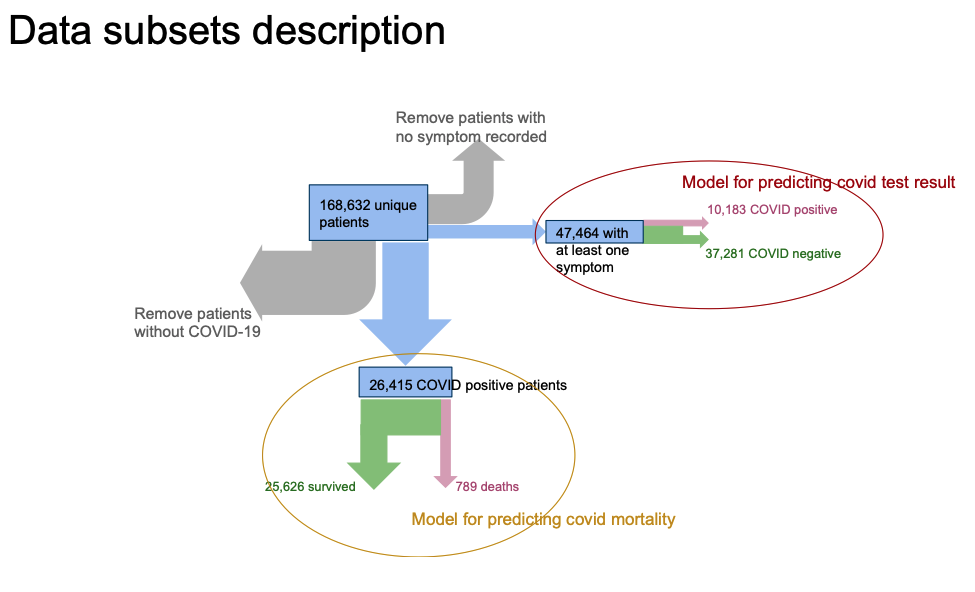
Data scientists with the Singapore MOHT evaluated detailed COVID-19 data from the Touchstone registry to identify patient factors linked to COVID-19 mortality (Figure 1).
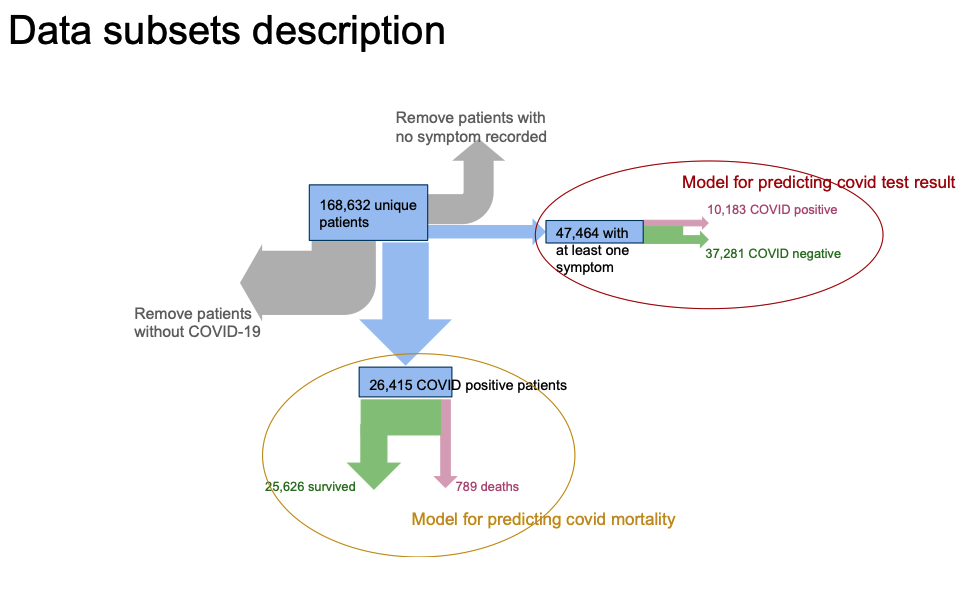
The Touchstone COVID-19 data set contained deidentified data for 168,632 unique patients. For comparison purposes, this dataset included patients with COVID-19-related symptoms and diagnoses. Of these unique patients, 47,464 exhibited at least one COVID-19-related symptom, approximately 21 percent of whom tested positive for COVID-19. Similarly, the data contained 26,415 patients who tested positive for COVID-19 (61 percent were either asymptomatic, or the treating facility didn’t document the symptoms). The COVID-19-related mortality rate for COVID-19-positive patients was approximately 3 percent (789 of 26,415).
The initial analysis effort focused on providing a triage tool for prioritizing care of patients exhibiting COVID-19-related symptoms. As Figure 2 shows, patients who tested positive for COVID-19 had different symptom distributions versus those who did not test positive. However, most patients were either asymptomatic or had no symptoms recorded. The small number of patients exhibiting loss of taste/smell is of particular interest to the MOHT, as this symptom has been seen as a strong indicator of COVID-19 in Singapore.
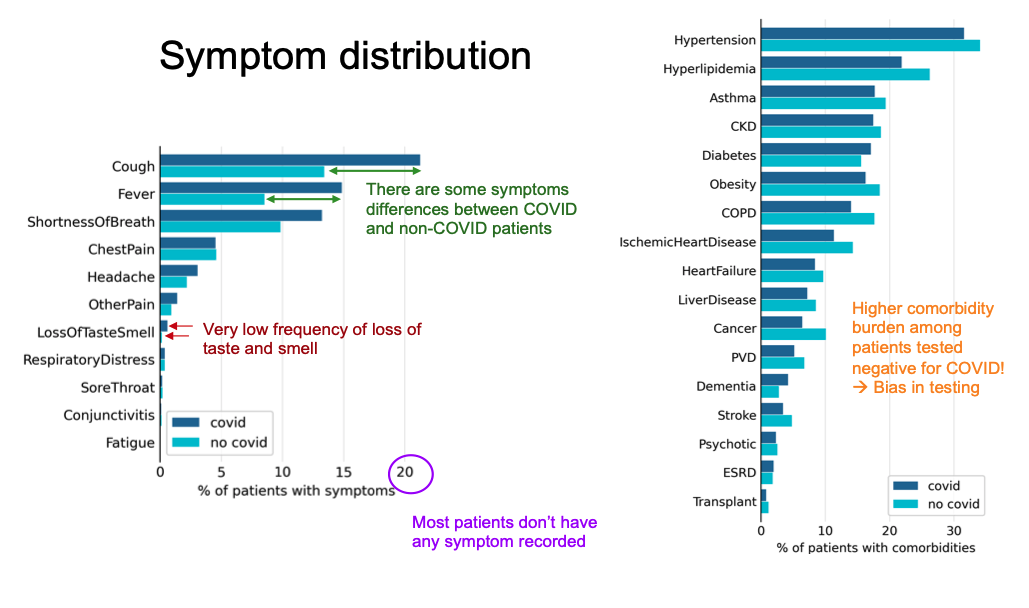
Despite the general lack of symptom data, when the MOHT researchers compared the correlation of symptoms to a positive COVID-19 test, two symptoms stood out: prior viral exposure and loss of taste/smell (the latter confirming what Singapore had determined through their testing regimes). Ultimately, the U.S. symptom data was too sparse to form the basis of a predictive model that could perform better than the literature-based, deterministic test result model that MOHT had already developed (Figure 3).
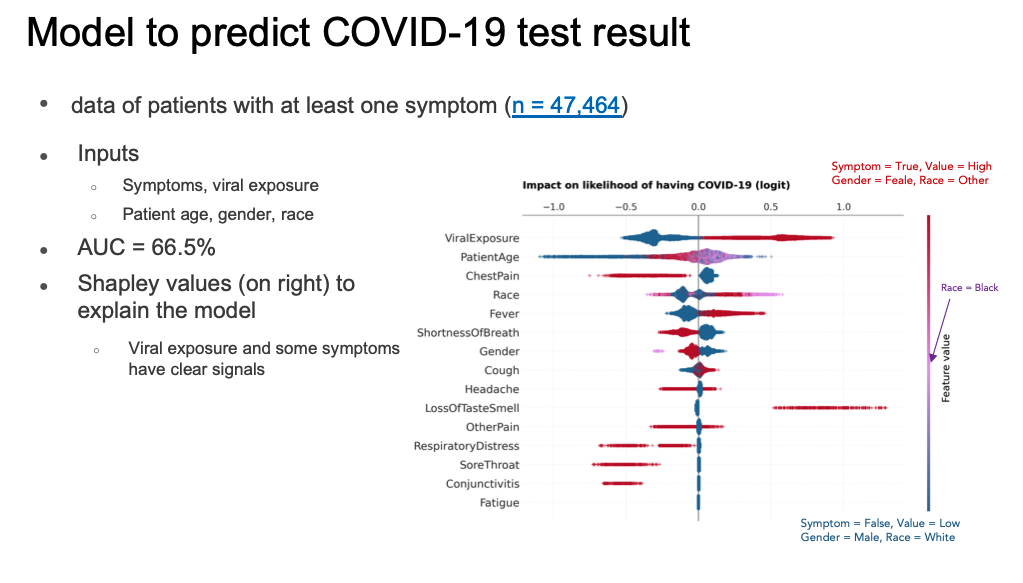
After the MOHT initial analysis efforts, the organization used factors such as age, race, gender, and comorbidities (including hypertension, cancer, and more), to produce a machine learning prediction tool to help clinicians identify COVID-19 patients at the highest risk of death (Figure 4). Some of the MOHT’s most meaningful insights include the following:
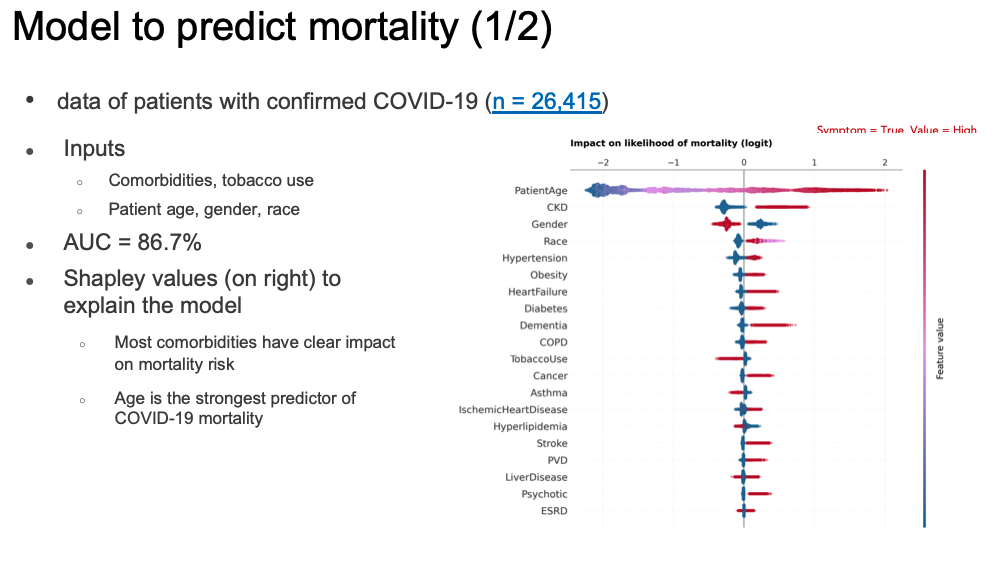
In contrast to the lack of symptom data captured, patient demographic and comorbidity data supported a mortality prediction model (an aggregate measure of performance across all possible classification thresholds, an AUC, of 86.7 percent). For the comorbidities in the chart above, red indicates existence of the condition, and blue indicates absence of the condition. As the values show, most comorbidities have an obvious impact on mortality risk.
However, comorbidity-based prediction is only useful if the analysts know a patient’s comorbidities. Therefore, given the observed impact of age, gender, and race in the comorbidity-based model, the MOHT data scientists created a second model using only those features likely universally available to clinicians: age, gender, race, and history of tobacco use. As Figure 5 shows, this model was performed nearly the same as the model with comorbidities (an AUC 85 percent versus the original AUC of 86.7 percent).

To verify the accuracy of the COVID-19 mortality prediction model, the MOHT reviewed published literature to compare the model’s outcomes with other research. The team determined its prediction model results were overwhelmingly consistent with other peer-reviewed studies.
The following lists offer examples of factors the MOHT model uses to predict COVID-19 mortality and some of the published literature that confirms their relationship to COVID-19 mortality:
One of the most promising uses of these COVID-19-data-drive prediction models may be in prioritization of viral testing in localities with insufficient resources. The first priority would be the allocation of COVID-19 tests to frontline healthcare workers and individuals in contact with a large number of people, such as cashiers and bus drivers. For the remaining population, the thresholds of risk for COVID-19 (given symptoms) and risk of death from the virus could determine test allocation. Similarly, these data-powered models may support early allocation of vaccines when they becomes available, as immunization among high-risk individuals maximizes the early impact of a vaccine.
Combining the Touchstone COVID-19 Registry and Insights aggregated data from U.S. healthcare providers with the expertise and experience of Singapore’s MOHT provided capability and insights neither organization could muster alone. The opportunities for global collaborations such as this are endless and create a huge opportunity for the research community at large to leverage real-world evidence to address global health issues and ultimately improve health outcomes.
Would you like to learn more about this topic? Here are some articles we suggest:
Would you like to use or share these concepts? Download the presentation highlighting the key main points.
Click Here to Download the Slides
https://www.slideshare.net/slideshow/embed_code/key/tYYOxNCbfWdRXx








