Healthcare organizations today have access to so much data from across their systems that they may struggle to know where to focus quality improvement efforts. An analytic framework and a stepwise process ensures organizations have broad data access and can identify the most significant opportunities for impact. With a strategic, data-informed approach to clinical quality improvement, health systems can consume fewer resources, discover cost savings, and improve ROI and the quality of care.
Three steps comprise an effective quality improvement process:
1. Adopt a healthcare-specific, open, scalable data platform.
2. Identify improvement priorities using the 80-20 rule.
3. Gain consensus from clinical teams on specific projects and goals.
 Download
Download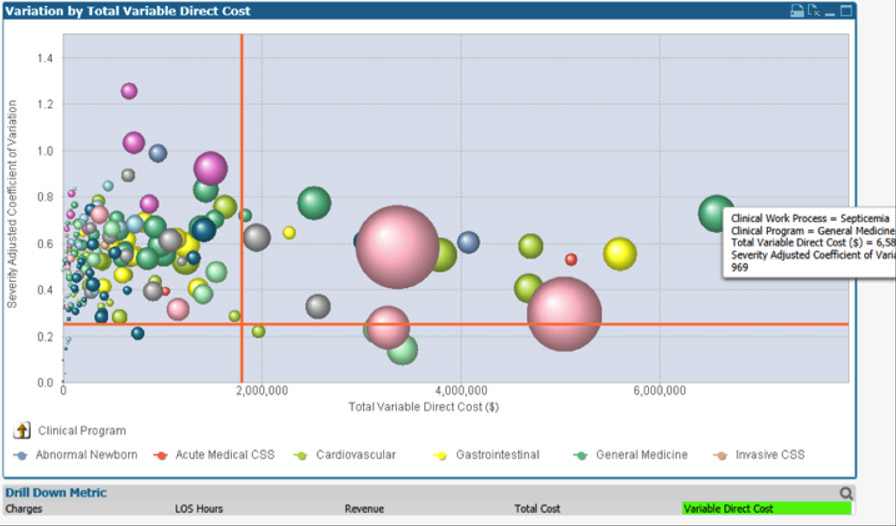
There’s a lot of discussion in today’s marketplace about clinical quality improvement in healthcare. But with so much data from various systems, such as administrative, research, clinical, human resources, etc., how do healthcare leaders begin to identify where to focus their quality improvement efforts?
Before launching quality improvement, organizations can eliminate the guesswork with an analytic framework, such as the Healthcare Analytics Adoption Model, and use quality data to drive any improvement decisions. By systematically advancing through the nine levels of the adoption model, any health system can use its data to streamline processes and accomplish the following:
With analytic resources in place, health systems can follow three steps for effective clinical quality improvement in healthcare:
A fundamental first step in quality improvement is adopting a healthcare-specific, open, flexible, and scalable data platform (e.g., the Health Catalyst Data Operating System (DOS™), Figure 1).
Figure 1: DOS.
Quality improvement success relies on the data platform because this resource extracts data from transactional source systems, combines disparate data sets into one source of truth, and queries the dataset directly. With a single source of truth, organizations have the foundation to drive clinical quality improvement initiatives and identify the areas in the organization that will yield the most significant improvements.
Many health systems have limited resources and can’t tackle all areas that need improvement at once. Instead, organizations can use a Key Process Analysis (KPA) application to focus their scarce resources where they’ll be most effective. The KPA tool uses the 80-20 rule (also known as the Pareto Principle)
to identify the 20 percent of care processes that 80 percent of resources consume.
Specifically, the KPA tool identifies the clinical processes with the highest variation and highest resource consumption. The tool combines clinical, billing, and costing data and links ICD-10 codes and all patient refined diagnosis-related groups (APR-DRGs) and other risk models. Additionally, the KPA application sorts each patient encounter into a three-tiered hierarchy:
With clinical data arranged in the three tiers above and combined with financial data, health systems can see which clinical programs, families, and work processes present the greatest opportunity for quality improvement. Improvement teams can then combine the analytical data with their knowledge of the organization to answer essential questions like the following:
For example, the KPA tool might show that 10 of an organization’s costliest care process families account for 48 percent of the direct variable cost in that health system. By identifying the costliest areas of care and studying the variations, improvement teams have identified potential focus areas. Insight into variation gives health systems a starting point for improvement. From here, organizations can follow the data and focus on the costliest clinical families, then move to other process families as they improve those high-impact areas.
Organizing information with the KPA tool also helps bring clinical teams on board with improvement efforts. Not only can clinical teams now view comprehensive data for the organization, but they can also view data specific to their specialty, which will help them define areas for improvement.
For example, the KPA tool might produce a visualization that plots clinical work processes against two axes: the total variable direct cost for all cases for that work process on the x-axis versus severity-adjusted variation in variable cost on the y-axis (Figure 2). The bubble size represents the case count for that clinical work process, and the upper right quadrant shows the work processes with the highest variation and cost.
Figure 2: Clinical work processes plotted against the variable direct cost (x-axis) and variation (y-axis).
The visualization in Figure 3 below displays the cost variation for a specific APR-DRG according to severity level. Each bubble represents a physician, and the bubble size is the case count. The position on the x-axis is the average variable direct cost per case by physician. The y-axis represents severity. Focusing on just the inlier for each level reveals wide variation.
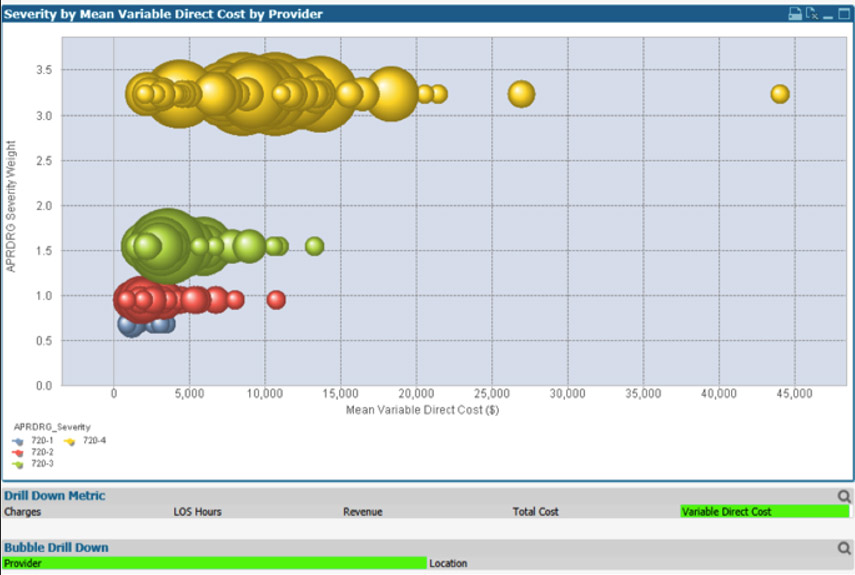
Figure 3: Case count by severity level for each physician.
Additional work with clinical teams can determine the root cause of the variations. Differences in documentation practices cause some variations, while in others, physicians and nurses deliver care in different ways for the same type of patient and condition. With team member consensus on priorities, the clinical teams can help determine the best ways to reduce variation while improving care.
As the healthcare industry continues to move to value-based purchasing, the transformation’s challenges will persist. Focusing on clinical and cost outcomes is critical. Having infrastructure and applications in place—such as an open data platform and a KPA tool—can support meaningful clinical quality improvement by enabling broad data access and identifying the most significant opportunities for impact.
Would you like to learn more about this topic? Here are some articles we suggest:
Would you like to use or share these concepts? Download this presentation highlighting the key main points.
https://www.slideshare.net/healthcatalyst1/three-steps-to-prioritize-clinical-quality-improvement-in-healthcare




