One of the biggest challenges health systems have faced since the onset of COVID-19 is the disruption to routine care. These care disruptions, such as halted routine checkups and primary care visits, place some patients at a higher risk for adverse outcomes. Health systems can rely on data science, based on past care disruption, to identify vulnerable patients and the short- and long-term effects these care disruptions could have on their health. Data science can also inform the care team which care disruptions to address first. With comprehensive information about care disruption on patients, health systems can apply the right interventions before it’s too late.
 Download
Download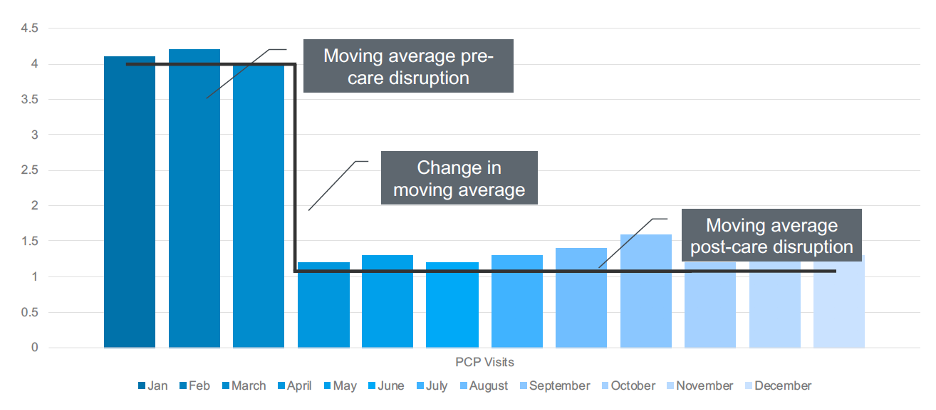
This article is based on a 2020 Healthcare Analytics Summit (HAS 20 Virtual) presentation by Imran Qureshi, Chief Information Officer and Chief Data Science Officer, b.well Connected Health, titled, “Navigating the Post-COVID World Through Data Science.”
As of January 2020-21, the pandemic has resulted in 76 million COVID-19 cases and over 1.6 million deaths, many of those healthcare personnel. In addition to these devastating outcomes and rising mortality rates, healthcare organizations face additional challenges from the pandemic’s major disruption in routine care. COVID-19 has impacted every area of healthcare: ambulatory practice visits have declined 60 percent while telehealth visits have increased; diagnostic testing has decreased as well as patients seeking care in a hospital setting; and hospitals nationwide have lost $60.1 billion a month, largely due to an unexpected stop in elective procedures.
These significant care disruptions have far-reaching effects on patients’ health, leaving organizations guessing about how to reach patients and deliver care when routine checkups stopped. Without these regular touchpoints, health systems struggle to identify and treat patients at a higher risk for adverse outcomes. While some people have stopped going to the doctor during the pandemic, patients with serious conditions, such as comorbidities and chronic diseases, can’t afford to miss routine visits. Conditions like diabetes and heart disease negatively impact a person’s immune system, putting them at higher risk for contracting COVID-19, other serious illnesses, and worse long-term health. The danger in delayed care can also lead to irreversible conditions, which providers and patients could have prevented with earlier involvement, and in some cases, an early death.
With so many unknown variables—vaccine development, adherence to face mask mandates, and social distancing guidelines—health systems can rely on healthcare data science to identify their most vulnerable patients and predict the effects of care disruptions on those patients. Predictive modeling, based on accurate data, provides visibility into at-risk patient groups, possible patient outcomes, and the best- and worst-case scenarios, helping health systems plan accordingly and prevent declining health.
In the new, fluid care landscape, health systems can tackle care disruption with data science-driven methods (e.g., machine learning and predictive models) to identify patients most affected by abrupt care delivery changes. With predictive models providing information about patients at the highest risk for worse outcomes due to care disruptions, health systems can apply early interventions and expend resources on patients with more complex care needs.
To identify patients at the highest risk for adverse outcomes from care disruptions, health systems can first identify care disruption in the past. Although not on the same scale as COVID-19, historical care disruption information (e.g., reduced primary care provider (PCP) visits or increased uninsured patients) is a starting point. Once health systems have gathered enough data sets to identify patients who have experienced care disruptions, they are ready to create predictive models.
To account for disruptions in care in predictive models, healthcare data science practitioners can include a specific care disruption as a feature in the model, such as listing a disruption in PCP visits (Figure 1). Including disruptions as features in the predictive model allows the algorithm to predict the impact of care disruption on future outcomes (e.g., total cost).

While the predictive models are only estimates, they are still powerful tools in helping health systems identify their most vulnerable populations. Focusing on the information a health system can access, such as the effects of the care disruption (e.g., stopped PCP visits), instead of focusing on the information a health system does not have (e.g., the impact of the cause of COVID-19 on outcomes), will help providers identify the patients at highest risk of adverse outcomes. Data science experts can also implement analysis techniques—such as oversampling, class balancing, zero inflation, and others—to account for having fewer positive samples in the past data compared to today.
After identifying and selecting a care disruption to include as a feature in the model, the next step is to convert the care disruption into a numeral to insert into the predictive models. To do so, data science teams must quantify each care disruption. It is up to each health system how to quantify each one. For example, one hospital could calculate the proportion of telehealth visits compared to normal visits or estimate the number of visits per month for emergency room, PCP, and specialist visits compared to last year’s visits.
Once a data scientist quantifies the care disruption, she must derive a number that reflects how much it has actually happened. The simplest way to think of this is to create a moving average. For example, a health system can create a three-month moving average to eliminate small variations, such as whether a patient went to the doctor on June 29 or July 2, but still accurately identify any changes in routine care.
As data scientists adjust this moving three-month average, they can identify when the change in the moving average was more significant than the threshold, resulting in care disruption (Figure 2). For example, in the graph below, something happened between March and April that decreased a patient’s moving average of four PCP visits per month to one visit per month. Healthcare data science teams can use this number to measure, or quantify, the change in this patient’s care, and then insert that number into the predictive model.
Measuring disruptions in care is the best place to start identifying high-risk patients, but it is not sufficient on its own. Another important tool in identifying patients at increased risk for adverse outcomes from COVID-19-induced changes to healthcare is case mix. Case mix includes health information such as chronic diseases and changes in cost or care over the past few years. Adding care disruptions and case mix as features in the predictive models allows for a more accurate prediction because the model can learn why two patients who look the same have different costs.
For example, if a health system has two patients, who both have the same reduction in PCP visits, data scientists should include each patient’s case mix in addition to the care disruption (i.e., reduced PCP visits). In this example, the case mix reveals that the first patient has diabetes and congestive heart failure, both chronic conditions that put him at risk for worse outcomes. The case mix would also show that the second patient is healthy, and the hospital does not need to apply interventions or include additional monitoring. With the case mix information, a health system can avoid wasting its limited resources, staffing, and supplies monitoring patients who do not need additional care.
With so many disruptions in care from the pandemic, data scientists need to understand which care disruption (e.g., a drop in PCP visits, loss of insurance, or an increase in ER visits) to address for each patient. Data science teams can use feature contribution, a concept in healthcare data science that takes a prediction and distributes that prediction to each feature, allowing teams to understand how much each feature contributes to the prediction. In the model below (Figure 3), care teams need to prioritize addressing the disruption in PCP visits because it is the greatest contributor to the outcome (in this case, total cost).

In addition to the impact of care disruption on patients, health systems can also use machine learning to understand how changes in care affect provider performance including safety, cost, and quality. Predictive models reveal how provider performance variations impact patients at a higher risk for adverse outcomes.
For example, Dr. Jones’s patients cost an average of $100,000, while Dr. Smith’s patients cost an average of $80,000 for the same procedure. At first, the data shows that Dr. Jones costs the health system more money, but additional data, such as the episode date, reveal that Dr. Jones’s patients received care before the pandemic and Dr. Smith’s patients after. The pandemic caused significant care disruptions, such as a halt in primary care visits and non-essential care (e.g., physical therapy), explaining the cost differential between the doctors instead of assuming that the difference is related to provider performance.
Because non-essential services stopped due to COVID-19, patients might have cost the health system more money because they received a full breadth of services before they were unavailable. With this information, leadership can use cost to learn which patients have not received complete services and if they are at higher risk for worse outcomes because of it.
With the novel coronavirus, health systems can no longer rely on the fundamental assumption of data science—that the future looks like the past. However, because care disruption has always been present in healthcare, even before COVID-19, health systems can use that information in predictive models to forecast future outcomes.
Care disruptions during the ongoing pandemic directly increase the risk of adverse outcomes for some patients. Health systems must identify these at-risk patients to implement the right care interventions before conditions worsen. Predictive modeling with varied data sets allows leaders to identify the patients at the highest risk of adverse outcomes from care disruptions and plan for different what-if scenarios. With data science, providers and their care teams can proactively intervene and avoid waiting until these high-risk patients come to the hospital.
Would you like to learn more about this topic? Here are some articles we suggest:
Would you like to use or share these concepts? Download the presentation highlighting the key main points.




